
Inteligencia
Artificial Generativa integrada al ecosistema digital
Un
marco de situación para la gubernamentalidad algorítmica
Generative
Artificial Intelligence integrated into the Digital Ecosystem
A
framework for Algorithmic Governmentality
Inteligência
Artificial Generativa integrada aoecossistema digital
Uma
estrutura de situação para a governamentalidade algorítmica
DOI:
https://doi.org/10.18861/ic.2025.20.1.3931
AGUSTINA
LASSI
alassi@unlam.edu.ar – Buenos Aires – Universidad Nacional de La Matanza, Argentina.
ORCID: https://orcid.org/0000-0003-3171-6258
CÓMO
CITAR: Lassi,
A. (2025). Inteligencia
Artificial Generativa integrada al ecosistema digital. Un marco de
situación para la gubernamentalidad algorítmica.
InMediaciones
de la Comunicación, 20(1).
https://doi.org/10.18861/ic.2025.20.1.3931
Fecha
de recepción: 20 de septiembre de 2024
Fecha de aceptación: 19 de febrero de 2025
RESUMEN
Este artículo analiza el avance de la integración de las Inteligencias Artificiales Generativas a las plataformas, sobre todo la que se basan en los modelos de lenguaje grandes (LLMs). Estos cambios comienzan a alterar la manera en que se produce y utiliza contenido, se busca y procesa información, y se gestionan los perfiles de los usuarios. El objetivo del artículo es realizar un mapeo de los principales desarrollos de LLMs en Occidente y sus asociaciones estratégicas, de hardware supply o financieras con plataformas, productores de hardware y servidores de cloud computing. En tal sentido, se parte del lanzamiento masivo de Chat GPT como momento fundacional de esta nueva etapa y se recorren los principales usos y aplicaciones de transformers en los entornos platafórmicos. Si bien estamos atravesando los comienzos de la aplicación de esta tecnología de manera integrada, podría generar una profundización en la personalización algorítmica, modificando las formas de subjetivación humanas y favoreciendo las burbujas epistémicas en el plano cognoscitivo, además de concentrar la oferta y el desarrollo en el plano de la economía política. Es por eso, que se plantea la necesidad de buscar más formas de intervención humana en la curación de datos e incrementar la observancia activa –tanto civil como gubernamental– de estos sistemas y sus alianzas para evitar la concentración extrema y atender a los sesgos que pudieran generar efectos negativos en la cultura.
PALABRAS CLAVE: inteligencia artificial, LLMs, gubernamentalidad algorítmica, plataformas, burbujas epistémicas.
ABSTRACT
This article analyzes the advancement of the integration of Generative Artificial Intelligences into platforms, especially those based on Large Language Models (LLMs). These changes are beginning to alter the way content is produced and used, information is searched and processed, and user profiles are managed. The aim of the article is to map the main LLM developments in the West and their strategic, hardware supply or financial partnerships with cloud computing platforms, hardware producers and servers. In this sense, we start with the massive launch of ChatGPT as the founding moment of this new stage and go through the main uses and applications of transformers in platform environments. Although we are at the beginning of the application of this technology in an integrated manner, it could generate a deepening of algorithmic personalization, modifying the forms of human subjectivation and favoring epistemic bubbles at the cognitive level, as well as concentrating supply and development at the level of political economy. That is why it is necessary to seek more forms of human intervention in data curation and to increase the active observance –both civil and governmental– of these systems and their alliances in order to avoid extreme concentration and to attend to the biases that could generate negative effects on culture.
KEYWORDS: artificial intelligence, LLMs, algorithmic governmentality, platforms, epistemic bubbles.
RESUMO
Este artigo analisa o avanço da integração das Inteligências Artificiais Generativas nas plataformas, nomeadamente nas que se baseiam em Modelos de Linguagem de Grande Dimensão (MLG). Estas mudanças começam a alterar a forma como os conteúdos são produzidos e utilizados, a informação é pesquisada e processada e os perfis dos utilizadores são geridos. O objetivo do artigo é mapear os principais desenvolvimentos de LLM no Ocidente e as suas parcerias estratégicas, de fornecimento de hardware ou financeiras com plataformas de computação em nuvem, produtores de hardware e servidores. Neste sentido, começa com o lançamento massivo do ChatGPT como momento fundador desta nova etapa e passa pelas principais utilizações e aplicações dos transformadores em ambientes de plataforma. Embora estejamos no início da aplicação desta tecnologia de forma integrada, ela poderá gerar um aprofundamento da personalização algorítmica, modificando as formas de subjetivação humana e favorecendo bolhas epistémicas ao nível cognitivo, bem como concentrando a oferta e o desenvolvimento ao nível da economia política. Isto suscita a necessidade de procurar mais formas de intervenção humana na curadoria de dados e de aumentar o controlo ativo, civil e governamental, destes sistemas e das suas alianças, a fim de evitar uma concentração extrema e de abordar os enviesamentos que podem gerar efeitos negativos na cultura.
PALAVRAS-CHAVE: inteligência artificial, LLMs, governação algorítmica, plataformas, bolhas epistémicas.
1.
INTRODUCCIÓN
El desarrollo de algoritmos de inteligencia artificial (IA) para la comprensión y generación del lenguaje ha sido un objetivo clave en las últimas dos décadas para las principales corporaciones tecnológicas de Oriente y Occidente. Este avance ha sido posible gracias al acceso masivo a datos de entrenamiento y al creciente poder de procesamiento proporcionado por las unidades de procesamiento de gráficos (GPU, por sus siglas en inglés)i. Así es que se ha avanzado intensamente en la investigación acerca del modelado del lenguaje, pasando de modelos estadísticos a modelos neuronales. Recientemente, se han introducido modelos lingüísticos pre-entrenados (PLM, por sus siglas en inglés) mediante transformers en grandes corpus, mostrando una gran capacidad para diversas tareas de procesamiento del lenguaje natural (NLP, por sus siglas en inglés). Se ha probado que aumentar la escala de los modelos mejora su rendimiento. Al incrementar la cantidad de parámetros, no solo mejoran significativamente en rendimiento, sino que también adquieren habilidades especiales (por ejemplo, aprendizaje contextual), algo que no ocurre en modelos más pequeños. Es esa capacidad de aprendizaje por contexto la que genera una suerte de “movimiento en las placas tectónicas” respecto a lo que pueden significar las nuevas capacidades de las plataformas que integran IA a su funcionamiento.
A partir del lanzamiento masivo de ChatGPT-3.5, en noviembre de 2022 por parte de Open AI, los Large Language Models (LLMs) –o modelos de lenguaje grandes– han sido objeto de fascinación y experimentación que exceden el ámbito académico y científico. El lanzamiento de Chat GPT redujo las barreras de acceso a los chatbots conversacionales y a otras formas de IA, marcando el inicio de una nueva etapa en la que el término “inteligencia artificial” se volvió de uso cotidiano. Detrás de esta tecnología se encuentran los transformers, la arquitectura que hizo posible su desarrollo. Un modelo transformer es una red neuronal que aprende contexto y significado mediante el seguimiento de relaciones en datos secuenciales. Aplica un conjunto de técnicas matemáticas, de atención propia, para detectar formas sutiles en que los elementos de datos en una serie se influencian y dependen entre sí. Los LLMs, o modelos de lenguaje grandes, son el componente clave detrás de la generación de texto. Consisten en transformadores entrenados previamente para predecir, dado un texto de entrada, la siguiente palabra (o, más precisamente, token). Dado que los modelos de lenguaje predicen un token a la vez, generar oraciones completas requiere un enfoque más elaborado que simplemente llamarlos una sola vez. Para ello, se emplea la generación autorregresiva, un procedimiento en el que el modelo es llamado iterativamente, utilizando sus propios resultados previos como insumo para continuar la secuencia y mejorar la coherencia del texto. En estos casos, el modelo genera secuencias de datos –como texto– utilizando sus propias salidas anteriores como nuevas entradas, comenzando con un conjunto de datos iniciales. Este proceso se repite iterativamente para producir una secuencia completa. Las potencialidades de aprendizaje maquínico asociadas a estos modelos son infinitas y generarán cambios en la manera en que comprendemos nuestro entorno y generamos conocimiento.
Los transformers se presentaron por primera vez en 2017 en la conferencia NeurIPS a través del documento de la empresa Google titulado “Attention is all you need”, dando inicio a una ola de avances en machine learning que algunos denominan como la “IA de transformer”ii. Ahora bien, los Generative Pre-trained Transformers (GPTs) son modelos de lenguaje natural que utilizan redes neuronales profundas para procesar y generar texto. Están diseñados para entender y producir lenguaje humano de manera similar a como lo haría un ser humano, aunque su conocimiento se deriva de vastos conjuntos de datos. El GPT más utilizado, el Chat GPT, cuenta con más de 200 millones de usuarios activos semanales –a noviembre de 2024iii– y tiene una interfaz simple en la cual el usuario (en su versión “gratuita”) puede acceder al historial de las interacciones con el chat de los últimos 7 días, ver conversaciones de ejemplo o ingresar texto con el prompt (instrucción o texto utilizado para interactuar con la IA), ya sea en voz o por medio del teclado. Algunas de estas organizaciones y/o empresas se dedican exclusivamente a fortalecer y entrenar más y mejor a estos modelos de lenguaje, mientras que otras los utilizan a modo de una Application Programming Interface (API) para desarrollar nuevos productos y servicios. En Occidente, existen en la actualidad más de 7000 empresas y organizaciones desarrollando software, aplicaciones y hardware con IA integrada. Las áreas en las que estas empresas se desempeñan son variadas, entre ellas: logística, finanzas, seguros, gestión crediticia, búsqueda, reventa, educación, aeroespacial y defensa, salud, atención al cliente, ciberseguridad, gaming, manejo de residuos, Information Technology (IT)iv y DevOpsv, automatización, agricultura.
En este artículo se observarán tres niveles de dinámicas en el avance de estas tecnologías. El primero, busca registrar las integraciones de las Inteligencias Artificiales Generativas de lenguaje e imágenes a software y hardware, así como a plataformas, y en ese marco reflexionará en torno al concepto de agencia editorial. En un segundo nivel, se analizarán las más reconocidas y pujantes StartUps de los LLMs de Estados Unidos y de otros países, así como sus vinculaciones con empresas platafórmicas de fabricación de hardware y servicios de cloud computing, para observar las vinculaciones entre dichas startups y las corporaciones que concentran las inversiones en estos desarrollos. Por último, el tercer nivel pretende ahondar en los tipos de vínculos (relaciones de interoperabilidad, asociación estratégica, servicio de nube o integración de IA) que se dan entre las principales corporaciones platafórmicas (Google, Microsoft, Meta, Amazon, Apple, X, Salesforce), las empresas productoras de microchips, GPU, Tensor Proccessing Unit (TPU)vi y las que ofrecen servicios de almacenamiento en la nube de manera de dar cuenta del escenario de interoperabilidad que propone este tipo de tecnologías y su efecto en las denominadas burbujas epistémicas.
A partir de esta propuesta, se pretende mapear el estado de situación actual de estas tecnologías por medio de una amplia, aunque no exhaustiva ni definitiva, sistematización de información. Los datos sistematizados en esta investigación fueron recopilados a partir del contenido de sitios oficiales, manuscritos cortos de compañías, videoconferencias, sitios de noticias especializados e informes y anuncios institucionalesvii. A través del uso de técnicas cualitativas como la revisión bibliográfica y el análisis de contenido, se pretende construir un bagaje de conocimiento actualizado acerca del estado de situación actual en torno a la integración y desarrollo de los LLMs. Este aporte es especialmente relevante en un campo donde la literatura sigue siendo limitada, salvo por algunos estudios clave. Entre ellos se encuentran los trabajos sobre la genealogía de la datificación digital y algorítmica en la IA (Gendler, 2024; 2021), la perspectiva analítica de los diferentes debates en torno a la conversación pública sobre las Inteligencias Artificiales Generativas y los LLMs (Costa et al., 2023) y los estudios acerca de la hiperautomatización, entendida como la próxima generación de automatización inteligente (Madakam, 2022).
2.
ANÁLISIS
2.1.
LLMs, agencia e integración
Los GPTs están diseñados para implementarse a través de APIsviii que permiten a los desarrolladores integrar sus capacidades en diversas aplicaciones y sistemas. Estas APIs facilitan la comunicación entre el GPT y otros programas, permitiendo la entrada de texto y recibiendo respuestas generadas por el modelo. Se apoyan en una arquitectura transformer que utiliza el procesamiento del lenguaje natural (NLP) y son pre-entrenadas con gran cantidad de textos sin supervisión. Luego, estos modelos se ajustan y especializan en tareas específicas. Su capacidad de aprendizaje continuo les permite expandir su alcance a múltiples ámbitos. De este modo, la integración de los LLMs en casi cualquier actividad humana plantea nuevos desafíos en cuanto a la propiedad y gestión de los transformers que procesan estos flujos de datos. Esto configura un vasto control sobre información altamente diversificada y específica, cuya recopilación sería mucho más difícil sin esta tecnología. La expresión cultura algorítmica de Striphas (2015) permite reflexionar acerca de este proceso: “Los seres humanos han estado delegando el trabajo de la cultura (…) crecientemente a procesos computacionales. Semejante cambio altera el modo en el que la categoría cultura ha sido hasta ahora practicado, experimentado y entendido” (p. 395). Así, la agencia humana, de acuerdo con la teoría del actor-red de Latour (1999), se invisibiliza y se limita. Implica por momentos la “supervisión”, la curación de datos de entrenamiento y la configuración de parámetros para adaptar el modelo a las necesidades específicas. De allí que los humanos también son responsables de validar la calidad de las salidas generadas por el GPT y de asegurar que cumplan con estándares éticos y prácticos. Pero al mismo tiempo, dichos LLMs representan una forma de agencia no humana en el sentido de que pueden tomar decisiones y realizar tareas cognitivas complejas sin intervención directa de las personas: pueden analizar datos, generar texto, realizar traducciones y responder preguntas de manera automatizada y eficiente. Pongamos como ejemplo lo que ocurre con la integración de LLMs a los motores de búsqueda. El algoritmo de indexación de Google, PageRank, toma decisiones basadas en un conjunto de criterios que evalúan el contenido de las páginas web para determinar el orden en que se presentan los resultados de búsqueda. A partir de esos resultados, el usuario elige en qué hipervínculo hacer clic para acceder a la información solicitada. Es decir, agencia humana y no humana trabajando de manera simple y colaborativa.
En dicha ecuación ya pesaban las implicancias relacionadas a los enlaces patrocinados y al sistema de monetización que impulsa Google como modelo de negocios con el Search Engine Optimization y el Search Engine Marketingix, aunque se puede suponer que la decisión ulterior es del ser humano –mediado por algoritmos, pero decidido por el ser humano–. Pero, ahora bien, ¿qué ocurre cuando se le integra Gemini al motor de búsqueda? La respuesta a esa pregunta configura, en parte, los grandes dilemas epistémicos de estos tiempos. Primer dilema: el AI Overview, nombre que se le da a la respuesta resumida sin realizar ningún click que brinda el motor de búsqueda como primera respuesta destacada. Este es un resumen automatizado por un modelo de lenguaje basado en criterios que son difíciles de determinar y rastrear, ya que dependen de la experiencia de búsqueda de cada usuario y del nivel de entrenamiento del LLM al momento de su uso. En este marco, el riesgo está en no comprender completamente los desafíos que la IA plantea para la agencia humana debido a las ambigüedades conceptuales que rodean al concepto de agencia. Para Floridi (2009), la agencia se refiere a la capacidad de los agentes (humanos o artificiales) para actuar de manera autónoma y tomar decisiones informadas dentro de la infoesfera, que es el entorno global de información. En tal sentido, la agencia no solo implica la capacidad de actuar, sino también la responsabilidad ética de las acciones realizadas. Un punto de partida lo proporciona la teoría del actor-red, que se centra en los “colectivos” (Latour 2007), no sólo de humanos sino también de conjuntos de humanos y objetos que, colectivamente, construyen lo social y, por lo tanto, poseen agencia. Tema que se conecta con la noción de la sociedad datificada, donde la construcción de la realidad se basa en la creación de sentido a partir de datos, lo cual ha impulsado un debate crucial sobre el poder de agencia, incluyendo la evolución de la agencia humana con el surgimiento de una agencia maquínica omnipresente (Hepp & Görland, 2024).
De este planteo teórico surge el segundo dilema: la agencia de Google –por seguir con el ejemplo– se torna central en la actividad de búsqueda de información, es decir, se torna en agencia editorial. Algo que hasta este momento era ampliamente debatido y refutado por las empresas tecnológicas que no consideran que sean responsables de generación de contenidox. Este salto epistémico ocurre, entonces, en dos niveles: 1) cognoscitivo, pues configura nuevas formas de definir la realidad establecidas y editorializadas por agencia no humana; 2) performativo, pues puede guiar a la acción a los seres humanos de maneras inimaginables y potencialmente nocivas para quien lo utilice.
De allí que este doble juego de agencia humana y no humana habilita a reflexionar con mayor profundidad en torno al concepto de gubernamentalidad algorítmica de Rouvroy & Berns (2015), una definición que observa de manera crítica el funcionamiento de la captación de datos en sistemas como los que ofrecen las plataformas. Los autores plantean que las características principales de este gobierno algorítmico son la creación de una dupla de lo real, un gobierno sin sujeto y un trabajo directo que limita o extrae los procesos de individuación de los sujetos, o su devenir. La gubernamentalidad algorítmica se caracteriza por un doble movimiento: el abandono de cualquier forma de “escala” a favor de una normatividad inmanente y evolutiva en tiempo real, de la cual emerge un “doble estadístico” del mundo que parece rechazar las viejas jerarquías establecidas por el hombre y la renuncia a cualquier confrontación con los individuos cuyas oportunidades de subjetivación se hallan, cuanto menos, enrarecidas. El valor de esta definición está en que pone como eje a las estadísticas contemporáneas en las relaciones y destaca la centralidad de las máquinas algorítmicas en los procesos de desarrollo tecnológico. Costa (2017) resalta la centralidad que tiene esta noción como grilla de inteligibilidad de las sociedades contemporáneas. Algo que, en los últimos años, resulta difícil de rebatir. En este sentido, van Dijck (2021) entiende que las complejidades de las plataformas están cada vez más desfasadas respecto de los estrechos conceptos legales y económicos en los que se basa su gobernanza y define los ecosistemas de información como estructuras jerárquicas e interdependientes. Esto inevitablemente pone el foco en cuestiones de poder, conflicto y explotación, una discusión que actualmente tiene lugar, por ejemplo, con respecto al capitalismo de vigilancia (Zuboff, 2019) y el colonialismo de datos (Couldry & Mejías, 2019).
Esta última característica se vio ampliamente profundizada por los movimientos de asociaciones y alianzas que ocurrieron entre Microsoft y OpenAI, Nvidia y Meta, Oracle y Microsoft, por mencionar algunas empresas, entre 2019 y 2024. Ejemplos de esto pueden ser la asociación de Microsoft con startups como Mistral AI y Alt.ai, o el uso que terceras partes hacen de la infraestructura provista por Open AI o Gemini (de Alphabet/Google) para sus desarrollos y mejoras (Widder, West & Whittaker, 2023). Sumado a estos movimientos, la incorporación de IA en las principales plataformas durante 2024 muestra el enorme interés de las corporaciones por realizar un fine-tuning de acuerdo con las necesidades de los usuarios. Muchas de estas integraciones en plataformas no brindan la posibilidad de que los usuarios opten por no utilizar sus servicios (optout) como, por ejemplo, la IA de Meta incorporada a WhatsApp e Instagram, lo que configura un listado enorme de países cuyos ciudadanos no tienen forma de proteger sus datos y su privacidad que no sea dejando de utilizar esos servicios por completo.
En la Tabla 1 se recopilan las más reconocidas y actualizadas integraciones de LLMs a diversos sistemas, aplicaciones y hardware en funcionamiento. Con este ejercicio se pretende rastrear el avance en el último año de la integración de estos sistemas al ecosistema digital.
Tabla
1. Integración
de IA a plataformas, software y hardware (2024)xi
*
Excepto en UE (pueden rechazar su instalación).
** Asociación
estratégica.
*** Integración del LLM de Open AI.
****
Utiliza los LLMs de Open
AI, Mistral y Anthropic.
*****
Para
iOS18, Ipad iOS 18.1 y Sequoia 15.1 (en Iphone 15 Pro y Iphone 16,
Ipads y Mac con chip M1 o más).
Fuente:
elaboración
propia.
2.2.
LLMs y vínculos corporativos concentrados
Lanzar herramientas de generación de texto, de imágenes y sonidos conlleva un riesgo asociado a los posibles resultados erróneos o maliciosos (deepfakes, fakenews, phising, entre otros) que las empresas parecieran no sopesar. El sistema occidental está en gran parte monopolizado por unas pocas empresas tecnológicas (Amazon, Alphabet, Meta, Apple, Microsoft). van Dijck, Poell y de Waal (2018) definen una plataforma como “una arquitectura programable diseñada para organizar interacciones entre usuarios” (p.9) y clasifican las plataformas en dos: las plataformas infraestructurales, que conforman los principales sistemas sociotécnicos para el intercambio de recursos, mensajes y contenidos, la coordinación de prácticas, movimientos y, especialmente, de los flujos de datos y comunicaciones. Cada una de ellas cumple el rol de brindar su infraestructura para un enorme abanico de plataformas específicas llamadas plataformas sectoriales –que no podrían operar sin esta base brindada por las infraestructurales–. Las sectoriales controlan cada vez más las puertas de ingreso del tráfico en Internet, la circulación de datos y la distribución de contenido, y asimismo logran eludir el escrutinio regulatorio convencional (Gillespie, 2018).
Helmond (2015) define la plataformización como la penetración de las extensiones de plataformas en la web y el proceso mediante el cual terceras partes habilitan sus datos para la plataforma. Interactúan las APIs, que facilitan el flujo de datos con terceros (complementadores) y los paquetes de desarrollo de software (los SDK, por sus siglas en inglés), que les permiten a terceros integrar su software con las infraestructuras de las plataformas (Helmond, Nieborg & van der Vlist, 2019). En conjunto, estas infraestructuras informáticas y los recursos informativos permiten relaciones institucionales que están en la raíz de la evolución y el crecimiento de una plataforma, ya que las plataformas proporcionan un marco tecnológico sobre el cual se puede construir (Helmond, 2015). Así, el paso de la concepción de estas tecnologías conceptualizadas como plataformas al análisis del accionar de estas como un proceso, dio lugar al concepto de plataformización, entendido como
la interpenetración de las infraestructuras digitales, los procesos económicos y los marcos gubernamentales de las plataformas en diferentes sectores económicos y esferas de la vida, así como la reorganización de las prácticas y los imaginarios culturales que existen en torno a estas plataformas. (Poell, Nieborg & van Dijck, 2022, p. 6)
La explosión de asistentes de IA aplicados a procesadores de texto, planillas de cálculo, motores de búsqueda (Copilot, Gemini), aplicaciones de chat como WhatsApp, redes sociales como Instagram (Meta AI-Llama) o X (Grok), y sistemas operativos (OS) para diversos hardwares como computadoras o smartphones (por ejemplo, Copilot o Samsung AI), demuestra lo relevante que resulta para estas empresas el entrenamiento que le proveen los usuarios individuales, buscando de esa manera mejorar la performance de estos sistemas. También obliga a pensar en los enormes volúmenes de datos que procesan estos sistemas y en la profundización del perfil de usuario que este uso provoca. ChatGPT 4-0, por ejemplo, está diseñado para reconocer el entorno en el que se encuentra el usuario e incorporar conocimiento acerca de sus preferencias y sus hábitos, que se mantienen y recuerdan en la performance del GPT de manera local –lo que Zuboff (2019) denomina excedente conductual–. Ese es un nuevo escalón en la gubernamentalidad algorítmica, entendida como “cierto tipo de racionalidad (a)normativa o (a)política que reposa sobre una recolección, agregación y análisis automatizado de datos en cantidades masivas de modo que se pueda modelizar, anticipar y afectar, por anticipación, los comportamientos posibles” (Rouvroy & Berns, 2015, p. 41).
Benjamin Bratton (2016) considera a las plataformas como las redes inteligentes, las nubes y las aplicaciones móviles que evolucionan, no como objetos separados, sino como un aparato computacional con una nueva arquitectura de gobierno con capas de diversos intereses. La concentración de actores encargados de desarrollar transformers, tanto en términos de programación como de entrenamiento y fabricación de hardware, abona la principal preocupación en torno a los dos ejes planteados en este trabajo: la profundización de los alcances de la gubernamentalidad algorítmica y la inevitable formación de burbujas epistémicas. Actualmente, son pocas las empresas que desarrollan y entrenan transformers, y prácticamente nulos los desarrollos por parte de Universidades, o centros de investigación de carácter público. Algunas de ellas son la Universidad del Sur de California y Georgia Tech. La National Science Foundation también realizó en 2024 fuertes inversiones en siete Institutos Nacionales de Investigación en IA recientemente establecidos en todo Estados Unidos, pero los volúmenes de dinero invertido son muy bajos en comparación con el mundo privadoxii. En el universo privado, las más reconocidas son Open AI (GPT), Microsoft (Copilot); Meta (Llama), Google (Gemini), X AI (Grok) y Apple (Apple Intelligence), todas ellas en asociación con el principal proveedor de Graphic Processor Units (GPU), Nvidia e Intel, entre otras. Vale aclarar que algunas empresas utilizan código de fuente abierto, como Meta (Llama), Hugging Face (BLOOM), Anthropic (Claude), Cohere (Command), Mistral (Mistral Large), Data Bricks (DBRX) y Perplexity (PPLX), la cual, además, funciona con conexión online a la web abierta. En ese marco, no se debe dejar de lado el ecosistema Oriental, principalmente chino y taiwanés, conformado por empresas como 01 Ai (Yi Series), H3C (ex Huawei), Inspur (Yuan), Tencent (Hunyuan), Alibaba (Tongyi Qianwen), el Instituto de Automatización de la Academia China de Ciencias y el Instituto de Inteligencia Artificial de Wuhan (Zidong Taichu), Zhipu AI (GLM-4), Moonshot AI (Kim), Baichuan, MiniMax (Abab) y Byte Dance (LLM en desarrollo, todavía no anunciada). Estas empresas representan un mercado muy competitivo y desafiante para el mercado norteamericano en el desarrollo de IA, como se ha demostrado con el lanzamiento del modelo R1 de Deepseek en enero de 2025, que causó pérdidas millonarias en la bolsa de valores a empresas productoras de microchips como NVIDIA por su enorme potencial con menores necesidades energéticas, monetarias y de procesamiento.
El universo de los LLMs es un universo mixto, en el que se mezclan estructuras de organizaciones sin fines de lucro (NPO, por sus siglas en inglés) con estructuras de ganancias limitadas (LLC, por sus siglas en inglés); otras son empresas privadas con interés de lucro (FPO, por sus siglas en inglés) y, algunas de ellas, conforman corporaciones de beneficio público (PBC, por sus siglas en inglés). Algunas ofrecen sus transformers, o sus modelos de manera abierta, es decir, Open Source (OS), otras son de código cerrado (CS, por sus siglas en inglés), mientras que muchas poseen tanta variedad de modelos que ofrecen ambas opciones al mercado de desarrolladores. Por una cuestión operativa, no se ha relevado si los pesos (weights) con los que han sido pre-entrenados los modelos son abiertos o cerrados, ya que depende mucho del tipo de modelo y política de la compañía desarrolladora que los mismos se compartan.
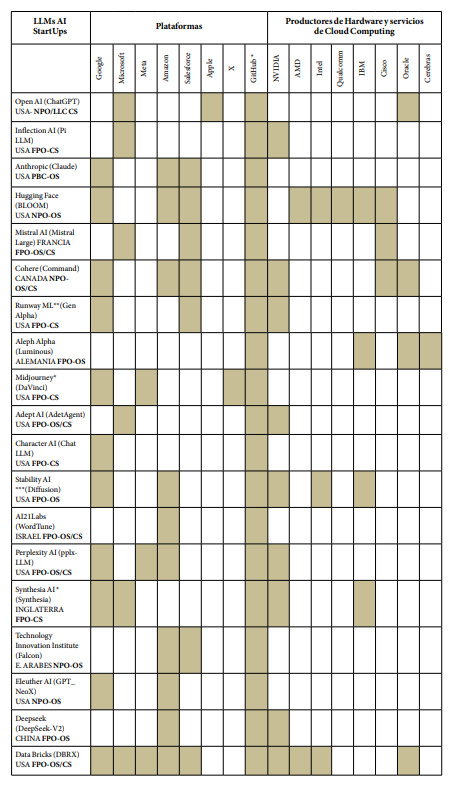
Como se desprende de este detalle de características que pueden asumir este tipo de organizaciones, la complejidad del escenario es considerable Sumado a ello, esta diversidad está asociada a grandes corporaciones con una larga trayectoria y un amplio reconocimiento. De allí que fue necesario reconstruir los nexos que existen entre ellas en la Tabla 2 a los efectos de que se puedan observar los vínculos que mantienen en la actualidad.
Tabla
2. Inversiones
y asociaciones en desarrollos de AI vinculados a LLMs (2024)xiii
*
Repositorio.
**
Text to Video, Image to Video and Text to Image.
***
Text to Video, Image to Video and Text to Image- Audio/3D.
Fuente:
elaboración
propia.
Los procesos de asociaciones estratégicas resultan vitales para este nuevo mercado. Así como Microsoft incorporó los servicios de OpenAI a sus productos ofreciendo hosting en Azure, su nube, Apple también cerró tratados en 2024 con OpenAI para asistir a Siri, su asistente de voz, en sus búsquedas de imágenes, mientras que Google hizo lo propio con Samsung AI al ofrecerle sus servicios de Google Lens y Nvidia firmó acuerdos comerciales para la producción de GPUs con Meta y X, por nombrar algunos ejemplos.
3.
LLMS, INTEROPERABILIDAD Y BURBUJAS EPISTÉMICAS
Los costos sociales y económicos de la concentración en el ecosistema digital configuran un problema global que sustenta la lógica económica de la extracción de datos que controla la vida de los consumidores occidentales (Couldry & Mejías, 2019). Esta concentración por acumulación –de hardware, insumos, tráfico y acumulación de datos y capacidades de entrenamiento– conlleva más retos que los exclusivamente vinculados con la acumulación excesiva y el procesamiento de la vida social en niveles nunca observados. Esto es, no sólo con fines comerciales y publicitarios, sino también con marcadas consecuencias epistémicas. Entrenar transformerses extremadamente caro y consume niveles de energía y agua potable muy elevados. Luccioni (2024) sostiene que, para la generación de 1000 imágenes, los modelos de IA de texto a imagen como DALL-E requieren 1.5 litros de agua por kilowatt de energía consumida. Además, el promedio de emisiones de CO2 per cápita es de aproximadamente 5 toneladas al año, mientras que el entrenamiento de un modelo Transformer grande, con búsqueda de arquitectura neuronal, emite 284 toneladas de CO2. Entrenar un único modelo base (sin ajuste de hiperparámetros) en GPUs requiere tanta energía como un vuelo transamericano (Strubell, Ganesh & McCallum, 2020). Y si bien parte de esa energía proviene de fuentes renovables o del uso de créditos de compensación de carbono por parte de empresas de computación en la nube, la mayoría de la energía de los proveedores de computación en la nube no proviene de fuentes renovables, lo que subraya la necesidad de arquitecturas de modelos y paradigmas de entrenamiento energéticamente eficientes.
Además, la disrupción y la innovación en la búsqueda no son gratuitas en términos monetarios. Los costos de entrenar un LLM son muy altos. Más importante aún, los costos de inferencia superan con creces los costos de entrenamiento cuando se implementa un modelo de estas características. De hecho, los costos de inferencia de ChatGPT superan semanalmente los costos de entrenamiento. Dylan Patel, analista jefe de la firma de investigación SemiAnalysis.com, relevó en un informe publicado en su sitio web, que a OpenAI le cuesta 36 centavos de dólar por consulta mantener su chatbot en funcionamiento hasta 2024. Es decir que estas empresas son conscientes de que el avance de estos modelos aplastará las ganancias generadas por venta de publicidad, por ejemplo, en los motores de búsqueda en un plazo muy corto. De allí que estén trabajando contrarreloj para incorporar IA a todos sus productos de cara a generar una mejora en sus modelos, reducir la latencia y aumentar el perfilamiento de usuarios por otros medios. Quien mejor y más rápido integre la IA, gana. Quien más rápido genere path dependance en sus usuarios, logrará imponer sus productos y servicios con mayor eficiencia. Algunos estudios insight de audiencias ya están observando que la implementación de IA en motores de búsqueda como Gemini en Google o Copilot en Bing ha alterado la cantidad de búsquedas que realizan los consumidores, la cantidad de resultados en los que hacen clic o la cantidad de tráfico que Google envía a la web abierta o a enlaces patrocinados tanto en la Unión Europea como en Estados Unidos, afectando su rentabilidad y su modelo de negocios (Fishkin, 2024).
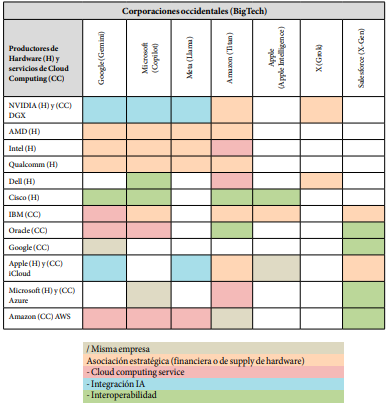
Como se observa en la Tabla 3, tanto las asociaciones estratégicas, como las posibilidades de interoperabilidad y las fuertes dependencias en términos de servidores, plantean un panorama de extrema concentración en muy pocos actores que debería ser especialmente atendido si se pretende paliar el efecto de la gubernamentalidad algorítmica.
Tabla
3. Relaciones
interempresariales en el mercado de IA occidental (2024)xiv
Todo lo expresado anteriormente también profundiza los efectos negativos de las burbujas epistémicas. Siguiendo a Nguyen (2020), las burbujas epistémicas conforman una estructura epistémica social en la que algunas voces relevantes han sido excluidas por omisión. Las burbujas epistémicas pueden formarse sin mala intención, a través de procesos ordinarios de selección social y formación de comunidades, lo que supone que la cooperación epistémica se está haciendo cuando los sujetos se comunican entre sí, pero también a través de la exclusión de determinados grupos o personas, o mediante la creación intencionada de entornos institucionales que llevan a los individuos a aceptar una perspectiva como la única viable. Esto último es lo que podría estar en desarrollo a partir de la integración de LLMs a las plataformas. Un efecto que hace que la información transmitida, repetida y elaborada genere un sistema amplificado de ideas y creencias en el que se omiten concepciones o perspectivas distintas a las del usuario (An, Quercia & Crowcroft, 2014). Además del efecto de agencia editorial de los agentes no humanos descrita anteriormente, estos modelos trabajan con bases de datos cerradas u obtenidas de la web, en el mejor de los casos, para generar un output en el que se reformulan los contenidos asociados al prompt específico. En Internet, el contenido en inglés domina más de la mitad de todo el contenido escrito en línea, a pesar de que sólo alrededor del 16% de la población mundial habla este idioma de acuerdo con la Internet Society Foundation (2023). Existen en el mundo más de 7.100 idiomas según el catálogo de Ethnologue (Ethnologue Newsroom, 2024). Llama 3.1 de Meta funciona sólo en 8 idiomas –al menos hasta julio de 2024–, Gemini 1.5 Flash está disponible en 40 idiomas, el GPT de Open AI, en su versión más avanzada, funciona en 50 idiomas y en algunos países como China, Rusia, Irán y otros del continente africano tiene un uso restringido o limitado. Escenario muy alejado del “círculo virtuoso de las IA” que anuncian empresas como Nvidia, por la cual cualquier aplicación que utilice datos de texto, imagen o video secuenciales es un candidato para los modelos de transformers.
Aunque investigar las propiedades de los modelos de lenguaje y cómo cambian con su tamaño tiene un interés científico, y los grandes LLMs han mostrado mejoras en varias tareas, no se ha reflexionado lo suficiente sobre los posibles riesgos asociados a su desarrollo e integración en plataformas y las estrategias para mitigarlos o frenarlos a tiempo. Habrá que observar de qué manera las empresas invierten, o no, en recursos para la curaduría y documentación cuidadosa de los conjuntos de datos en lugar de ingerir todo lo que está en la web, reduciendo el riesgo de “los loros estocásticos” y, por ende, los efectos de la burbuja epistémica.
La tendencia humana a atribuir significado al texto, junto con la capacidad de los grandes modelos de lenguaje para aprender patrones asociados con diversos sesgos y actitudes perjudiciales, presenta riesgos de daño real si se difunde texto generado por estos modelos. (Bender et al., 2021, p. 618)
Los peligros del texto sintético están profundamente relacionados con el hecho de que dicho texto puede entrar en conversaciones sin que ninguna persona o entidad asuma la responsabilidad. También pueden tener “alucinaciones” generando contenido inexistente presentado como real. Esta responsabilidad incluye tanto la veracidad como la importancia de contextualizar el significado. Es por ello, que considerar poner a prueba previo a la salida al mercado masivo estos modelos con una importante intervención humana en todas sus fases será muy importante de cara a evaluar cómo la finalidad del modelo se ajusta a los objetivos de investigación y desarrollo y apoya los valores establecidos (Bender et al., 2021).
4.
CONCLUSIONES
La rapidez con que se implementan los nuevos desarrollos en IA hace que sea muy difícil seguirles el ritmo a quienes realizan investigación en el área. La información no es transparente, muchas veces no se explicita en el material periodístico que las narra y a veces hasta se configura como un secreto entre partes. Sumado a esto, el dinamismo de las asociaciones, fusiones y acuerdos interempresariales obligan a considerar un marco de observancia más atento y detallado si se pretende comprender quiénes y de qué manera se controlan estos sistemas y se acrecienta su poderío. Más que nunca, es necesario comprender en mayor profundidad cómo funciona la plataformización y mapear los escenarios que contribuyan a repensar los marcos de gobernanza compartimentados en un enfoque más holístico, tal como sugiere van Dijck (2021).
La integración de los LLMs en plataformas podría ampliar el alcance de la gubernamentalidad algorítmica ya que permite una mayor recopilación y análisis de datos, lo que a su vez fortalece la capacidad de las plataformas para modelar, predecir y responder a los comportamientos de los usuarios. Al ser integrados en motores de búsqueda como Google (Gemini) o Bing (Copilot), estos modelos de lenguaje modifican la forma en que los usuarios acceden a la información. La opacidad de los criterios utilizados por los algoritmos para seleccionar y presentar la información otorga a las plataformas una agencia editorial significativa, lo que plantea dilemas éticos y epistémicos. Esto se ve aumentado por la creciente capacidad de los LLMs para recordar (memories) y utilizar información sobre las preferencias y hábitos de los usuarios a nivel local profundiza aún más el concepto de excedente conductual, descrito por Zuboff (2020). Como pudo observarse en las tablas elaboradas, es de vital importancia de analizar este contexto en el marco de la plataformización, puesto que estas tecnologías amplificaran la interpenetración de infraestructuras digitales, en los procesos económicos y marcos gubernamentales, en la organización de la información y las interacciones en línea aumentando la concentración del poder y el control sobre los datos y la información en manos de unos pocos.
La personalización algorítmica, acelerada por la integración de LLMs en las plataformas, contribuye a la formación de burbujas epistémicas. Al basarse en conjuntos de datos limitados y en las preferencias de los usuarios, los modelos de lenguaje generativos pueden brindar resultados que refuercen las ideas preexistentes y limiten la exposición a perspectivas diferentes. Además, la predominancia del idioma inglés en los contenidos online y la limitada disponibilidad de LLMs en otros idiomas agravan este problema, creando barreras lingüísticas para el acceso a la información y la diversidad de perspectivas.
Con la rápida integración de la IA, y en particular de los LLMs, en las plataformas digitales se nos presentan desafíos importantes y urgentes. La concentración del poder demostrada por las asociaciones y alianzas en las tablas generará una profundización de las formas en que se ejerce la gubernamentalidad algorítmica, problemática que requiere una mayor atención por parte de investigadores, legisladores y la sociedad en general. Todo esto ocurre en un marco poco regulado, que avanza a un ritmo difícil de seguir y que corre la barrera del límite constantemente. Ello, sumado a la falta de transparencia en el desarrollo y funcionamiento de estas tecnologías, así como la velocidad con la que se están integrando en diversos ámbitos de la vida, dificultan la posibilidad de un debate público informado y la implementación de medidas de control y regulación efectivas. La creciente delegación de procesos cognitivos a las tecnologías asociadas con la IA muestra ser un problema acuciante en nuestras sociedades, no sólo por la creación de burbujas epistémicas sino porque podría amplificar desigualdades sociales, culturales, económicas y políticas al mismo tiempo que es responsable de la mayor proliferación de sesgos raciales y discriminatorios difíciles de contrarrestar con igual velocidad y potencia. Será tarea de la academia y de los investigadores implicados en estos desarrollos afinar la mirada crítica y dedicarse a comprender estos fenómenos con la mayor especificidad posible.
REFERENCIAS
An, L., Quercia, D. & Crowcroft, J. (2014). Partisan sharing: Facebook evidence and societal consequences. Proceedings of the Second ACM Conference on Online Social Networks, 13-24. https://dl.acm.org/doi/abs/10.1145/2660460.2660469
Bala, M. & Verma, D. (2018). A Critical Review of Digital Marketing. International Journal of Management, IT & Engineering, 8(10), 321-339. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3545505
Bender, E., Gebru, T., McMillan-Major, A. & Mitchell, M. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Conference on Fairness, Accountability and Transparency, 610-623. https://doi.org/10.1145/3442188.3445922
Bratton, B. H. (2016). The stack: On software and sovereignty. MIT press.
Costa, F. (2017). Omnes et singulatim en el nuevo orden informacional. Gubernamentalidad algorítmica y vigilancia genética. Poliética, 5(1), 40-73. https://doi.org/10.23925/poliética.v5i1.36356
Costa, F., Mónaco, J. A., Covello, A., Novidelsky, I., Zabala, X. & Rodríguez, P. (2023). Desafíos de la Inteligencia Artificial Generativa: Tres escalas y dos enfoques transversales. Question, 76(3), e844. https://doi.org/10.24215/16696581e844
Couldry, N. & Mejias, U. (2019). Data colonialism: rethinking big data’s relation to the contemporary subject. Television & New Media, 20(4), 336-349. https://doi.org/10.1177/1527476418796632
Ethnologue Newsroom (2024). Languages of the World. Ethnologue. http://www.ethnologue.com
Fishkin, R. (2024). Zero-Click Search Study: For every 1,000 EU Google Searches, only 374 clicks go to the Open Web. In the US, it’s 360. SparkToro. https://sparktoro.com/blog/2024-zero-click-search-study-for-every-1000-us-google-searches-only-374-clicks-go-to-the-open-web-in-the-eu-its-360/
Gendler, M. (2024). Datificación social e inteligencia artificial: ¿hacia un nuevo “salto de escala”? Resonancias, 17, 121-141. https://doi.org/10.5354/0719-790X.2024.74503
Gendler, M. A. (2021). Mapeando la dataficación digital y algorítmica: Genealogía, estado de situación y nuevos desafíos. InMediaciones de la Comunicación, 16(2), 17-33. https://doi.org/10.18861/ic.2021.16.2.3166
Gillespie, T. (2018). Custodians of the Internet. Yale University Press.
Helmond, A. (2015). The Platformization of the Web: Making Web Data Platform Ready. Social Media + Society, 1(2). https://doi.org/10.1177/2056305115603080
Helmond, A., Nieborg, D. B. & van der Vlist, F. N. (2019). Facebook’s evolution: Development of a platform-as-infrastructure. Internet Histories, 3(2), 123-146. https://doi.org/10.1080/24701475.2019.1593667
Hepp, A. & Görland, S. O. (2024). Agency in a datafied society: an introduction. Convergence, 30(3), 945-955. https://doi.org/10.1177/13548565241254692
Internet Society Foundation (2023). ¿Cuáles son los idiomas más utilizados en Internet? Fundación Noticias. https://www.isocfoundation.org/es/2023/09/cuales-son-los-idiomas-mas-utilizados-en-internet/
Langlois, G., McKelvey, F., Elmer, G. & Werbin, K. (2009). Mapping commercial Web 2.0 worlds: Towards a new critical ontogenesis. Fibreculture, 14(2009), 1-14. https://fourteen.fibreculturejournal.org/fcj-095-mapping-commercial-web-2-0-worlds-towards-a-new-critical-ontogenesis/
Latour, B. (2007). Reassembling the Social: An Introduction to Actor-Network-Theory. OUP Oxford.
Latour, B. (1999). On Recalling ANT. The Sociological Review, 47(S1), 15-25. https://onlinelibrary.wiley.com/toc/1467954x/1999/47/S1
Luccioni, S., Jernite, Y. & Strubell, E. (2024). Power hungry processing: Watts driving the cost of AI deployment? The 2024 ACM Conference on Fairness, Accountability and Transparency. https://dl.acm.org/doi/abs/10.1145/3630106.3658542
Madakam, S., Holmukhe, R. M. & Revulagadda, R. K. (2022). The next generation intelligent automation: hyperautomation. JISTEM-Journal of Information Systems and Technology Management, 19, e202219009. https://doi.org/10.4301/S1807-1775202219009
Nguyen, C. T. (2020). Echo chambers and epistemic bubbles. Episteme, 17(2), 141-161. https://doi.org/10.1017/epi.2018.32
Poell T., Nieborg D. & van Dijck, J. (2022). Plataformización. Revista Latinoamericana de Economía y Sociedad Digital, 1-27. https://doi.org/10.53857/tsfe1722
Rouvroy, A. y Berns, T. (2018). Gobernabilidad algorítmica y perspectivas de emancipación: ¿lo dispar como condición de individuación mediante la relación?. Ecuador Debate, 104: 124-147. http://hdl.handle.net/10469/15424
SemiAnalysis (2024). The Inference Cost Of Search Disruption – Large Language Model Cost Analysis. https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
Striphas, T. (2015). Algorithmic Culture. European Journal of Cultural Studies, 18(4-5). https://doi.org/10.1177/1367549415577392
Strubell, E., Ganesh, A. & McCallum, A. (2020). Energy and policy considerations for modern deep learning research. Proceedings of the AAAI conference on artificial intelligence, 34(9), 13693-13696. https://doi.org/10.1609/aaai.v34i09.7123
van Dijck J., Poell T. & De Waal M. (2018). The Platform Society. Oxford University Press.
van Dijck, J. (2021). Seeing the forest for the trees: Visualizing platformization and its governance. New Media & Society, 23(9), 2801-2819. https://doi.org/10.1177/1461444820940293
Widder, D., West, S. & Whittaker, M. (2023). Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI. SRRN. http://dx.doi.org/10.2139/ssrn.4543807
Zuboff, S. (2019). The Age of Surveillance Capitalism: The Fight for the Future at the New Frontier of Power. Profile Books.
*
Contribución de autoría: la
conceptualización y el desarrollo integral del artículo fue
realizado por
la autora.
* Nota: el Comité Académico de la revista aprobó la publicación del artículo.
* El conjunto de datos que apoya los resultados de este estudio no se encuentran disponibles para su uso público. Los datos de la investigación estarán disponibles para los revisores, si así lo requieren.
![]()
Artículo
publicado en acceso abierto bajo la Licencia CreativeCommons -
Attribution 4.0 International (CC BY 4.0).
IDENTIFICACIÓN
DE LA AUTORA
Agustina
Lassi.
Doctoranda en Ciencias Sociales, Universidad de Buenos Aires
(Argentina). Magister en periodismo, Universidad de Buenos Aires.
Docente-Investigadora, Universidad Nacional de La Matanza
(Argentina), Universidad Nacional de Avellaneda (Argentina),
Universidad Nacional Guillermo Brown (Argentina) y Universidad
Nacional Arturo Jauretche (Argentina). Su
área de investigación son los estudios sociotécnicos sobre
plataformas digitales.
i La sigla GPU –o unidad de procesamiento gráfico– refiere a los procesadores diseñados para manejar y acelerar el procesamiento de gráficos e imágenes en dispositivos como tarjetas de video, placas base, teléfonos móviles y computadoras personales. Al realizar cálculos matemáticos rápidamente, reduce la cantidad de tiempo necesario para que una computadora ejecute múltiples programas, lo que la convierte en un habilitador esencial de tecnologías emergentes y futuras como el aprendizaje automático (ML), la IA y blockchain.
iiVéase: https://neurips.cc/Conferences/2017
iv IT: sistemas y herramientas digitales que se utilizan para procesar, almacenar, transmitir y proteger la información.
v DevOps: combina las palabras en inglés development (desarrollo) y operations (operaciones). Es un conjunto de prácticas y herramientas que busca mejorar el desarrollo de aplicaciones y la publicación de nuevas funciones de software.
vi TPU –unidad de procesamiento tensorial– es un tipo de circuito integrado de aplicación específica (ASIC) desarrollado por Google. Está diseñado para acelerar las tareas de aprendizaje automático y redes neuronales artificiales, especialmente optimizado para trabajar con Tensor Flow, la biblioteca de código abierto para aprendizaje automático. Las TPUs son conocidas por su alta eficiencia y rendimiento en el procesamiento de grandes volúmenes de datos, lo que las hace ideales para aplicaciones de IA y aprendizaje profundo.
vii Algunos de los sitios consultados fueron: https://openai.com/about/ - https://www.nvidia.com/es-la/ - https://www.ibm.com/es-es/artificial-intelligence - https://www.salesforce.com/es/company/news-press/press-releases/ - https://ai.meta.com/ - https://deepmind.google/technologies/gemini/ - https://aws.amazon.com/es/ai/ - https://www.anthropic.com/news
viii Langlois et al. (2009) describen a las APIs –o interfaz de programación de aplicaciones– como componentes cruciales en el desarrollo de la Web 2.0, facilitando el surgimiento de plataformas al permitir interacciones de software modulares y recursivas. Enfatizan el papel de las APIs en la creación de intercambios estructurados entre componentes de software, permitiendo que los datos se compartan, automaticen y redistribuyan dentro de la cultura computacional. Las interfaces de programación de aplicaciones son conjuntos de protocolos y herramientas que permiten la comunicación y el intercambio de datos entre diferentes sistemas de software. Así, las APIs facilitan la integración y la interoperabilidad, permitiendo que los desarrolladores accedan a funcionalidades de otros programas sin necesidad de conocer su código interno).
ix La optimización de motores de búsqueda –o SEO–, es esencialmente ajustar su sitio web para que aparezca de forma natural u orgánica en los resultados de búsqueda en Google, Bing o cualquier otro motor de búsqueda para figurar en el Search Engine Results Page (SERP). El marketing en buscadores –o SEM– es la estrategia integral para dirigir el tráfico a un sitio, principalmente a través de esfuerzos pagos. En función de las posibilidades y objetivos, se puede elegir el Modelo PPC (pago por clic) o CPC (coste por clic) o CPM (coste por mil impresiones) (Bala & Verma, 2018).
x Ni lo hace la legislación vigente en la Sección 230 del Acta de Comunicaciones de 1995. Sobre esa ley, véase: https://www.congress.gov/bill/104th-congress/senate-bill/314
xi Los datos presentados en esta tabla son parciales y, si bien pretenden ser exhaustivos, no representan la totalidad del panorama de integraciones sino aquellas que más afectan el funcionamiento del ecosistema platafórmico hasta diciembre de 2024.
xii El anuncio del proyecto Stargate, entre Open AI, Oracle y SoftBank, con el auspicio de la administración Trump (enero 2025) contempla la colaboración con universidades y centros de investigación para fomentar la educación en inteligencia artificial. Al parecer, esta reciente iniciativa no solo busca impulsar la economía, sino también asegurar que EE.UU. mantenga su liderazgo tecnológico a nivel global frente al marcado avance de los desarrollos en China.
xiii Los datos presentados en esta tabla son parciales. Si bien pretenden ser exhaustivos, no representan la totalidad del panorama de inversiones y asociaciones efectuados a la fecha de la publicación de este artículo. La lista original estaba conformada por 20 StarUps. Una de ellas, MosaicML, fue adquirida por Databricks en el proceso de elaboración de esta investigación por lo que fue eliminada de la tabla. Estas 20 organizaciones representan los desarrollos más avanzados en Transformers. Nótese que de las 19, 12 son de origen estadounidense, número que muestra la enorme concentración de los desarrollos en un solo país. Según el AI Index Report de 2024, elaborado por la Standford University, Estados Unidos lidera el listado de desarrollos notables en LLMs en el mundo con un total de 61, seguido por China con 15, Francia con 8, Alemania con 5 y Canadá con 4. Véase: https://hai.stanford.edu/research/ai-index-report
xiv Los datos presentados en esta tabla son parciales. Si bien pretenden ser exhaustivos, no representan la totalidad del panorama de relaciones interempresariales en el mercado Occidental, sino aquellas más vinculadas al escenario platafórmico que interesa construir.